Kafka高性能的原因
Kafka读写快的原因分析。
分区
充分利用集群的优势,提升io性能。
顺序写磁盘
Kafka 的整个设计中,Partition 相当于一个非常长的数组,而 Broker 接收到的所有消息顺序写入这个大数组中。同时 Consumer 通过 Offset 顺序消费这些数据,并且不删除已经消费的数据,从而避免了随机写磁盘的过程。
而删除过程,并非通过使用“读 - 写”模式去修改文件,而是将 Partition 分为多个 Segment,每个 Segment 对应一个物理文件,通过删除整个文件的方式去删除 Partition 内的数据。这种方式清除旧数据的方式,也避免了对文件的随机写操作。
充分利用PageCache
引入 Cache 层的目的是为了提高 Linux 操作系统对磁盘访问的性能。Cache 层在内存中缓存了磁盘上的部分数据。当数据的请求到达时,如果在 Cache 中存在该数据且是最新的,则直接将数据传递给用户程序,免除了对底层磁盘的操作,提高了性能。
使用 Page Cache 的好处:
- I/O Scheduler 会将连续的小块写组装成大块的物理写从而提高性能
- I/O Scheduler 会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间
- 充分利用所有空闲内存(非 JVM 内存)。如果使用应用层 Cache(即 JVM 堆内存),会增加 GC 负担
- 读操作可直接在 Page Cache 内进行。如果消费和生产速度相当,甚至不需要通过物理磁盘(直接通过 Page Cache)交换数据
- 如果进程重启,JVM 内的 Cache 会失效,但 Page Cache 仍然可用
Broker 收到数据后,写磁盘时只是将数据写入 Page Cache,并不保证数据一定完全写入磁盘。从这一点看,可能会造成机器宕机时,Page Cache 内的数据未写入磁盘从而造成数据丢失。但是这种丢失只发生在机器断电等造成操作系统不工作的场景,而这种场景完全可以由 Kafka 层面的 Replication 机制去解决。如果为了保证这种情况下数据不丢失而强制将 Page Cache 中的数据 Flush 到磁盘,反而会降低性能。也正因如此,Kafka 虽然提供了 flush.messages 和 flush.ms 两个参数将 Page Cache 中的数据强制 Flush 到磁盘,但是 Kafka 并不建议使用。
零拷贝技术
Kafka 中存在大量的网络数据持久化到磁盘(Producer 到 Broker)和磁盘文件通过网络发送(Broker 到 Consumer)的过程。这一过程的性能直接影响 Kafka 的整体吞吐量。
- Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入
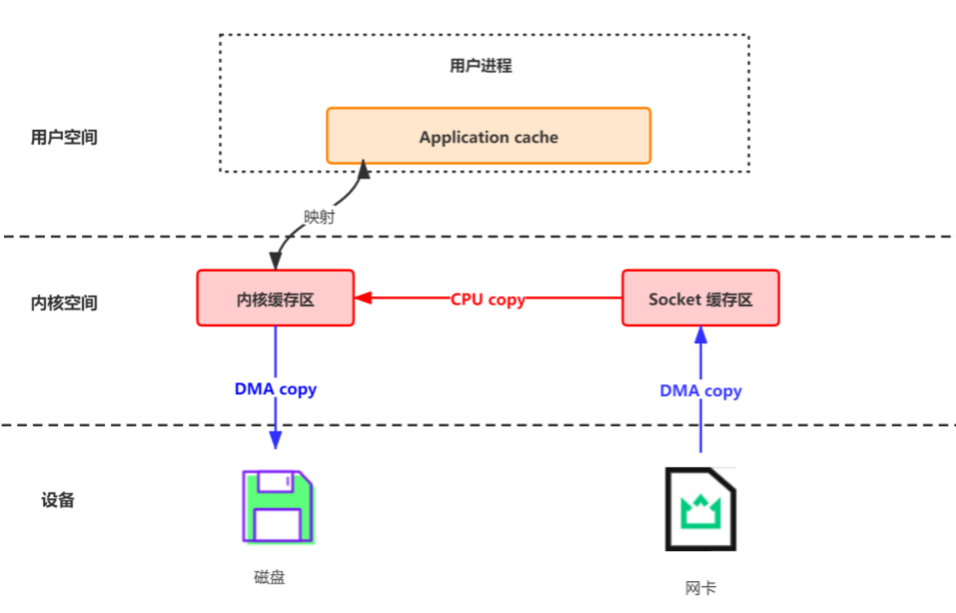
- Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗

批处理
在很多情况下,系统的瓶颈不是 CPU 或磁盘,而是网络 IO。
因此,除了操作系统提供的低级批处理之外,Kafka 的客户端和 broker 还会在通过网络发送数据之前,在一个批处理中累积多条记录 (包括读和写)。记录的批处理分摊了网络往返的开销,使用了更大的数据包从而提高了带宽利用率。
 微信
微信 支付宝
支付宝

